Niekiedy bywa zjawiskiem szkodliwym, ale znacznie częściej jest bardzo istotną składową dźwięków o charakterze muzycznym, w znacznym stopniu definiującą brzmienie. Przyjrzymy się bliżej temu zjawisku, zobaczymy, jak uzyskać szum, a także kiedy i gdzie należy go brać pod uwagę jako czynnik niepożądany. Szum jako zjawisko akustyczne występuje pod różnymi postaciami: jako szum pracy urządzeń, szum zurbanizowanego otoczenia, część dźwięków natury, a w bardziej kontrolowanej formie jako element składowy dźwięków muzycznych. Ze zjawiskiem szumu spotkamy się też w każdym urządzeniu odtwarzającym dźwięk przez głośniki lub słuchawki – jest on nieodłączną częścią przepływu prądu w układach elektronicznych, a więc także we wzmacniaczach zasilających przetworniki elektromagnetyczne. Funkcjonuje on nawet tam, gdzie nie płynie prąd, ale mamy do czynienia z przewodnikiem prądu, którego temperatura jest wyższa od temperatury zera absolutnego. Wynika to z faktu istnienia zjawiska ruchów Browna, czyli wzajemnego pobudzania do samoistnych drgań cząsteczek znajdujących się w jednorodnym środowisku.
Szum ze swej natury jest zjawiskiem chaotycznym, ale można go na różne sposoby ustabilizować. Jeśli przyjmiemy, że szum – w naszym wypadku akustyczny – składa się z nieskończonej liczby dyskretnych sygnałów sinusoidalnych o różnej częstotliwości, to rozkład energii tych częstotliwości będzie definiował charakter szumu. Ów rozkład będzie wynikał z właściwości źródła lub źródeł szumu oraz parametrów filtrów, które będą go kształtowały. Jak zwykło się mówić, „lepszy przykład niż wykład”, a takim przykładem niech będzie... muszla. Mowa o muszli morskiej, rzecz jasna. Niektórzy twierdzą, że przykładając ją do ucha usłyszymy szum akwenu, z którego ona pochodzi. To bardzo romantyczne i pobudzające wyobraźnię, ale w rzeczywistości mamy tu do czynienia z tym, o czym napisałem wyżej: źródłem szumu, czyli szumem otoczenia, oraz mechaniczną filtracją pod postacią rezonującego wnętrza muszli. I to właśnie ono sprawia, że szum otoczenia zostaje odfiltrowany, na ogół gdzieś w przedziale 200-800 Hz. Ponieważ wylot tego mechanicznego rezonatora skierowany jest prosto do naszego ucha, następuje zmiana proporcji między szerokopasmowym szumem otoczenia, a szumem odfiltrowanym. Zjawisko to pogłębione jest przez różnice w widmie i fazie tego samego szumu odbieranego przez jedno i drugie ucho. Resztę robi nasz mózg i wyobraźnia, i w ten właśnie sposób słyszymy „szum oceanu”.
W celach technologicznych i pomiarowych wprowadzono zunifikowaną filtrację szumu akustycznego, dostosowując ją do różnych potrzeb. Dla zdefiniowania rodzajów szumu posłużono się matematyką, ale w zakresie realizacji dźwięku aż tak zaawansowana wiedza nie jest nam potrzebna. Dość powiedzieć, że szum biały zawiera w sobie wyrównane energetycznie spektrum częstotliwości audio. Jest zatem „najszerszy” brzmieniowo, ale też niezbyt przyjemny w odsłuchu. Z kolei szum różowy ma charakterystykę ukształtowaną tak, że bardzo dobrze odpowiada właściwościom naszego słuchu, przez co wydaje nam się najbardziej zrównoważony. Słucha się go przyjemnie, a ponadto ma tę właściwość, że już po kilkunastu sekundach wyrównuje ustawienia naszych „filtrów w mózgu”, niejako kalibrując system słyszenia. Jest jeszcze kilka innych rodzajów szumów opisywanych na ogół jakimś kolorem, dość jednoznacznie kojarzącym się z jego brzmieniem. Nie są one jednak tak często wykorzystywane w praktyce jak biały i różowy. Szum w układach elektronicznych może być pochodną nieintencjonalnego szumu własnego ich elementów (jest wtedy niepożądany), albo wytworzony celowo. To ostatnie na ogół realizuje się poprzez użycie odpowiednio spolaryzowanego złącza półprzewodnikowego z tranzystora lub diody. Jednak rozrzut charakterystyk szumowych poszczególnych elementów bywa tak różny, że trudno tu mówić o dającej się kontrolować powtarzalności. Zdecydowanie lepiej wygląda to w domenie cyfrowej, ale okazuje się, że wygenerowanie szumu o wyrównanej charakterystyce wymaga dokonania tylu obliczeń, że proces ten bywa mocno obciążający dla procesora.
Mamy tu oczywisty paradoks – szum, którego nie chcemy, bierze się praktycznie znikąd i pojawia się wszędzie, a szum pożądany uzyskuje się dużym nakładem sił i środków. Dokładnie jak w domowym ogródku – chwasty rosną bujnie bez naszej ingerencji, a uprawa roślin użytkowych i ozdobnych wymaga wiele pracy. Działa to też w drugą stronę, bo zwalczanie chwastów jest wyjątkowo kłopotliwe i pracochłonne, a te rośliny, na których nam naprawdę zależy, można bardzo łatwo zniszczyć.
Szum użyteczny
Szum znajduje bardzo szerokie zastosowanie w produkcji muzycznej. Generator dźwięków tego typu znajdziemy w niemal każdym syntezatorze, jest też podstawowym źródłem sygnału elektronicznych instrumentów perkusyjnych. Zazwyczaj wykorzystuje się go pod postacią dźwięku o charakterze impulsowym, który kształtujemy z wykorzystaniem dwóch modulatorów: obwiedni głośności i/lub filtracji sterowanej obwiednią. W naszym pierwszym przykładzie wykorzystamy go do ukształtowania stworzonego we własnym zakresie dźwięku werbla typu 808, posługując się w tym celu modułami z syntezatora Voltage firmy Cherry Audio. Użyjemy generatora szumu, dwóch generatorów tonu, filtrów i obwiedni, z których pierwsza będzie kształtowała impulsowy charakter szumu, a druga tonu podstawowego. Potem do ubarwienia partii syntetycznego basu wykorzystamy odstrajaną w samplerze próbkę szumu, filtrowaną pasmowo w zależności od wysokości dźwięku. Ustawiając optymalne odstrojenie, parametry i modulację filtracji, a także aplikując efekty, uzyskamy dodatkową warstwę brzmieniową, istotnie wzbogacającą sonicznie naszą partię basu.
TR-808 Snare
Wyjątkowo słaby i zupełnie nieprzekonujący dźwięk werbla z legendarnej maszyny perkusyjnej Roland TR-808 stał się swoistym znakiem firmowym dla wielu współczesnych gatunków muzycznych. Będąc zaprzeczeniem wszystkiego tego, czego wymaga się od werbla w produkcjach o charakterze rockowym, w muzyce elektronicznej zrobił nieprawdopodobną wręcz karierę i zyskał status porównywalny tylko z pozycją, jaką w branży ma dźwięk kick, pochodzący z tego samego instrumentu.
Od strony elektronicznej jest to konstrukcja tyleż prosta, co genialna. Opiera się na dwóch rezonujących filtrach w układzie typu T, pobudzanych do drgań gasnących sygnałem wyzwalającym o dwóch poziomach: normalnym i akcentowym. Wytwarzają one fale o częstotliwościach ok. 170 i 340 Hz, które po zmiksowaniu regulatorem SD Tone pozwalają uzyskać szereg dodatkowych tonów harmonicznych. Do takiego sygnału dodawany jest bramkowany sygnał szumu białego o obwiedni kształtowanej regulatorem Snappy.
Jakkolwiek dźwięk ten w swojej ogólnej formie bardzo łatwo można uzyskać za pomocą syntezatorów modularnych, to już dobór odpowiednich parametrów dla uzyskania właściwego brzmienia wymaga szeregu eksperymentów. Zaprezentowana w artykule metoda generowania werbla typu 808 z wykorzystaniem Voltage Modular okazuje się jednym z najskuteczniejszych sposobów pozyskania tego typu barw bez uciekania się do samplingu. Ponadto daje ona bardzo duże możliwości w zakresie dopasowania brzmienia do naszych potrzeb, jakich nie ma oryginał ani żaden instrument wirtualny emulujący słynne automaty TR.
Krok po kroku
1. Werbel w stylu 808

1.
W samodzielnej wersji programu Cherry Audio Voltage kliknij prawym klawiszem myszy na wolnym polu raka i zaimportuj Noise Generator, Amplifier i PSP Nitro BQF, za pomocą których uzyskasz składową szumową, dwa moduły Oscillator, Ladder Filter i Amplifier dla składowej tonalnej oraz 8 Step Sequencer, Six-Input Mixer i dwie obwiednie Envelope.

2.
Sekwencer posłuży do wygenerowania impulsów wyzwalających. Wykorzystaj jego wyjście Gate, kierując je na wejścia Gate w obu obwiedniach Envelope. Ich wyjścia natomiast włącz do wejść CV In w obu modułach Amplifier. Każdy zestaw obwiednia-wzmacniacz będzie kształtował impulsowy charakter sygnałów z oscylatorów.
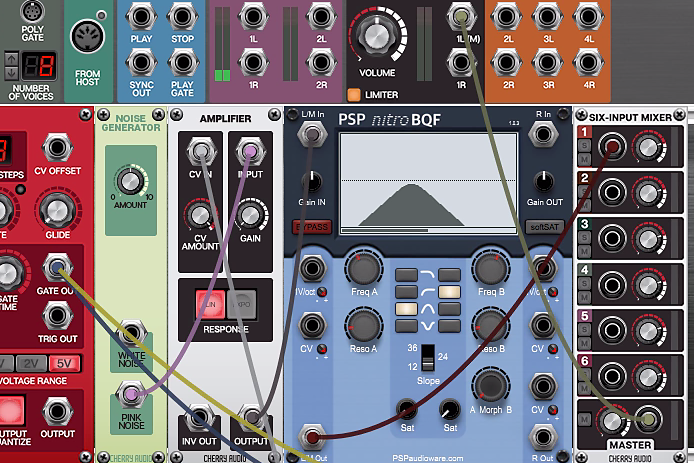
3.
Wyjście Pink Noise włącz na wejście jednego z modułów Amplifier, jego wyjście na filtr PSP Nitro BQF z charakterystyką pasmowoprzepustową, a wyjście filtru z kolei na jedno z wejść miksera Six-Input. Sygnał wyjściowy Master z miksera skieruj na port 1L(M) modułu Main Outs, w ustawieniach programu wskazując wcześniej interfejs audio, którego używasz.

4.
Sygnał tonalny generują dwa oscylatory – ton wyższy ustaw na 2’ (-7), a niższy na 8’ (+5). Wyjście oscylatora wyższego tonu sinusoidalnego skieruj bezpośrednio na wejście drugiego modułu Amplifier. Wyjście sygnału trójkątnego oscylatora tonu niższego skieruj na to samo wejście Amplifier za pośrednictwem filtru Ladder. Wyjście Amplifier podaj na mikser.

5.
W obu generatorach obwiedni ustaw czasy Decay i Release na około 450 ms, suwaki Attack i Sustain ustawiając na 0. Kształtujący szum filtr BQF powinien mieć częstotliwość odcięcia ok. 2,5 kHz i nieznaczny rezonans. Na wejścia modulujące 1V/oct podaj wyjście z obwiedni szumu, ustawiając znajdujący się przy gnieździe regulator na ok. 0,2, a nachylenie na 12 dB.

6.
W sekwencerze pozostaw aktywne przyciski 1 i 5. Wciśnij w mikserze przycisk Solo na wejściu składowej tonalnej i włącz odtwarzanie sekwencera. W filtrze Ladder ustaw odcięcie na ok. 400 Hz, rezonans na 30% i Saturation na 80%. Poeksperymentuj z czasami obwiedni składowej tonalnej, nieznacznie skracając i wydłużając Decay i Release.

7.
Na brzmienie tonu podstawowego wpływ ma ustawienie filtru Ladder oraz częstotliwości ustawiane regulatorami Frequency w obu modułach Oscillator. Ta składowa brzmienia werbla powinna być dostrojona do tonacji utworu. Najłatwiej to uzyskać regulatorem Frequency dla niższego tonu, odstrajając następnie ton wyższy o 2 oktawy w górę względem niższego.

8.
Teraz włącz w tryb solo wejście miksera dla składowej szumowej. Zadaniem modulacji częstotliwości odcięcia filtru jest jej chwilowe odstrojenie w górę na samym początku dźwięku. Brzmienie szumu i jego obwiednia wpływają na czytelność werbla w aranżacji. Ostatecznego szlifu barwy werbla dokonasz za pomocą filtru BQF.

9.
Wykorzystaj jego część B, ustawiając tryb górnoprzepustowy 400 Hz, rezonans 30%, saturację 80%, Morph 40% i włączając SoftSat. Ustawieniami filtracji BQF, głębokością modulacji Freq A i proporcjami na wejściach miksera dobierz odpowiadające Ci brzmienie. Włączając Voltage jako wtyczkę w DAW możesz dokonać tego w kontekście aranżacji.
Krok po kroku
2. Szum w partii basu
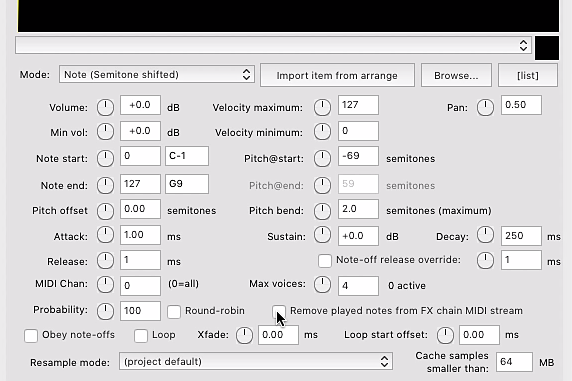
1.
Korzystamy z Reapera, ale możesz użyć dowolnego DAW i jego funkcji komutacji, jeśli tylko zastosowany sampler pozwala na przepuszczanie podawanych na jego wejście komunikatów MIDI. Dostępny w Reaperze ReaSamplOmatic5000 (RS5K) powinien mieć odznaczoną opcję Remove played notes from FX chain MIDI stream.
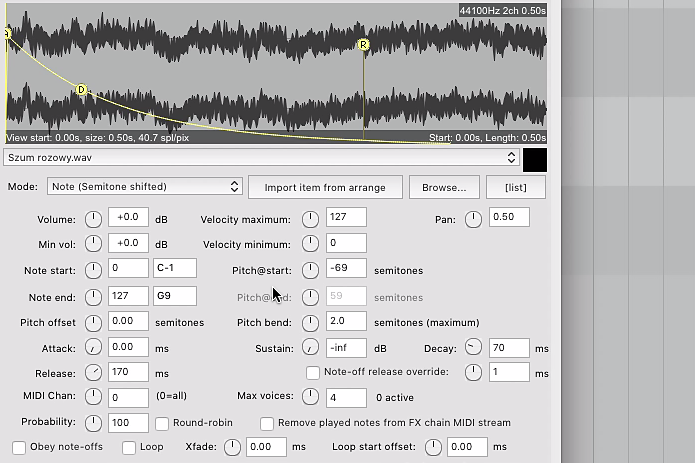
2.
Na ścieżce włącz syntezator basowy (w naszym przypadku to NI TRK-01 Bass) i zaprogramuj partię, którą ma grać. Na nowej ścieżce włącz RS5K, zaimportuj do niego próbkę szumu z materiałów dodatkowych na DVD i aktywuj tryb Note. Ustaw Attack na 0, Release na 170 ms, Sustain na minimum, Decay na 70 ms, a w Resample wybierz Lowest.
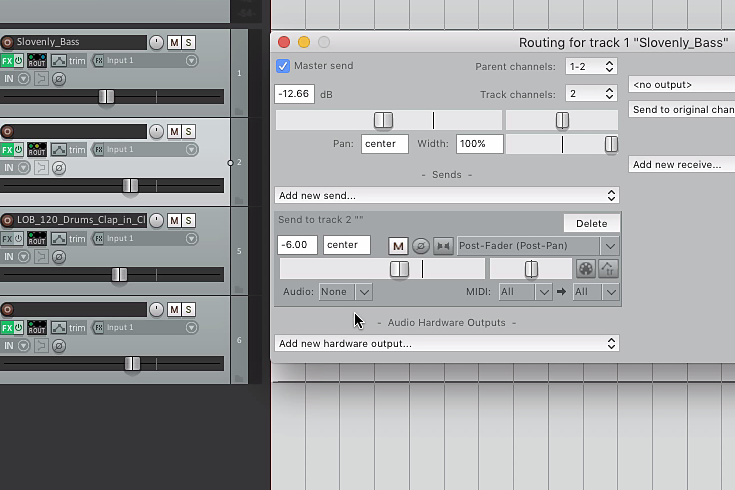
3.
W komutacji ścieżki syntezatora dodaj wysyłkę na ścieżkę z RS5K, wyłączając audio i zostawiając tylko MIDI. Po uruchomieniu odtwarzania, dźwiękowi basu powinien towarzyszyć odstrajany szum z samplera. Upewnij się, że sampler reaguje na wszystkie nuty MIDI: kontrolka Note Start powinna być ustawiona na 0 (C-1), a Note End na 127 (G9).
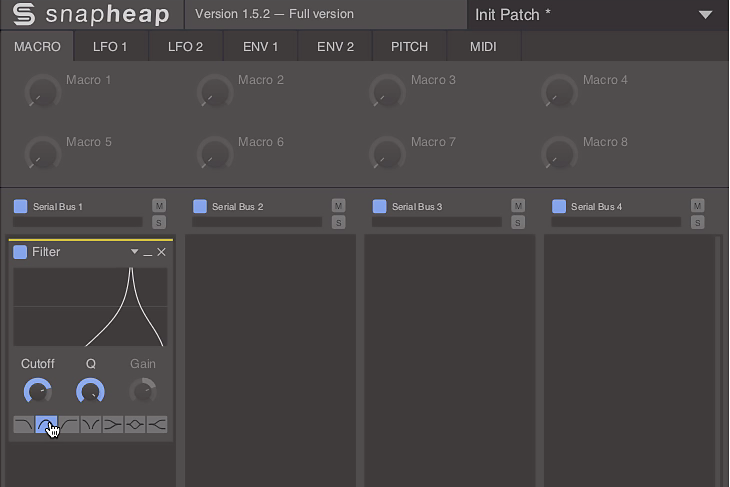
4.
Za samplerem włącz wtyczkę Snap Heap (do pobrania ze strony www.kilohearts.com, a z dodatkowymi wtyczkami dostępna na DVD i online w ramach Pakietu EiS). Kliknij na pierwszym wolnym slocie i wybierz procesor Filter. Włącz tryb pasmowoprzepustowy, ustaw Cutoff na ok. 4 kHz, a kontrolkę parametru dobroci filtracji (Q) przekręć na maksimum.
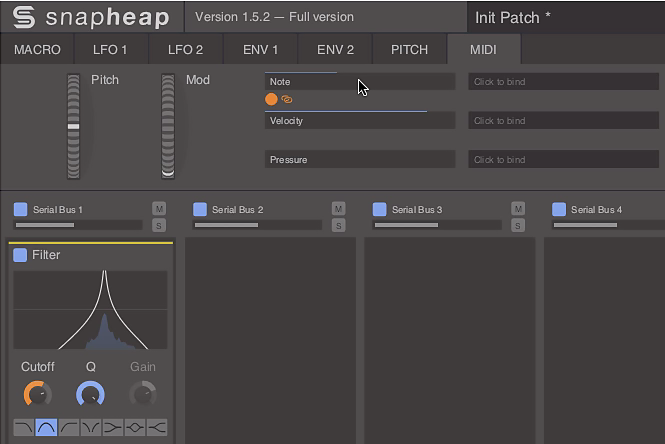
5.
Częstotliwość filtracji będzie modulowana wysokością nut MIDI. W Snap Heap kliknij zakładkę MIDI. Po ustawieniu kursora na polu Note kliknij ikonę spinaczy, która pojawi się poniżej. Pod regulatorami pokażą się pomarańczowe kółka przypisania – przeciągnij maksymalnie w górę na kółku pod Cutoff i kliknij pole Note, aby zatwierdzić przypisanie.
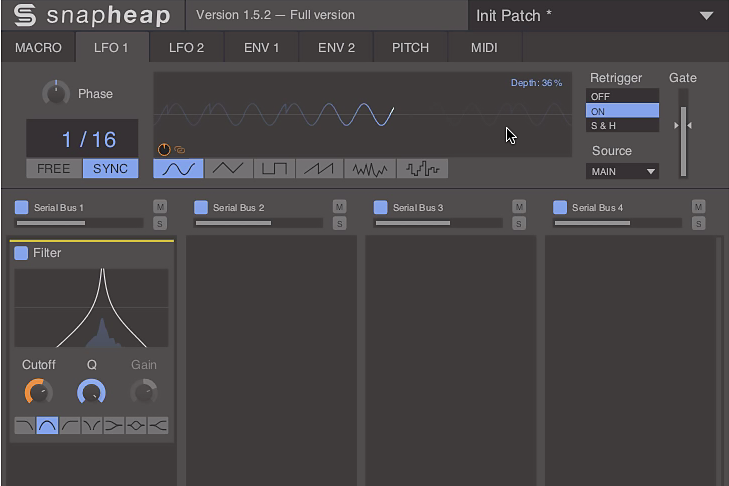
6.
Gdy teraz włączysz odtwarzanie, partii basu będzie towarzyszyć składowa szumowa, której wysokość będzie się zmieniać wraz z kolejnymi dźwiękami. Dodaj do niej subtelną modulację, klikając zakładkę LFO 1, podobnie jak wyżej przypisując modulator z głębokością ok. 1%. W LFO ustaw Sinus, Sync 1/16, Depth 34% i Retrigger On.
Szum niechciany
Jak już wspomniano wyżej, szum pojawia się wszędzie tam, gdzie płynie prąd elektryczny. Największy problem stwarza on w urządzeniach, w których mamy do czynienia z dużym wzmocnieniem sygnału, głównie w przedwzmacniaczach mikrofonowych. Ich zadaniem jest wzmacnianie niewielkiego sygnału z mikrofonu do poziomu liniowego, co oznacza zastosowanie układów wzmacniaczy napięciowych o wzmocnieniu kilku, a nawet kilkunastu tysięcy razy. Wraz z sygnałem użytecznym wzmocnieniu ulega także towarzyszący im szum oraz przydźwięk. Razem ze zniekształceniami nieliniowymi sygnału użytecznego, będącymi jego częstotliwościami harmonicznymi, tworzy on swoisty dźwiękowy „muł”, określany w danych technicznych urządzeń jako THD+N (całkowite zniekształcenia harmoniczne i szum). Parametr ten wyrażany jest najczęściej w procentach lub decybelach. Pojawia się tu spore pole nie tyle do nadużyć, co do stosowania nieprecyzyjnych lub nie do końca oczywistych danych. W praktyce, wartość THD+N powinna oznaczać odstęp, czyli wyrażoną w decybelach różnicę między poziomem nominalnym sygnału (w praktyce +4 dBu, -10 dBV lub 0 dBfs) a zsumowanym wynikiem pomiaru szumów własnych i zniekształceń wprowadzanych przez urządzenie. Pomiaru należy dokonywać przy sygnale wejściowym o takim poziomie, by na wyjściu uzyskać poziom nominalny, w którym następnie określa się zawartość obu tych elementów, czyli zniekształceń i szumów.
Redukcja szumu
Wiele osób szumem określa wszystko, co nie jest dźwiękiem, a to nie do końca prawda. Gdy mowa o sygnałach zakłócających, szum nie jest jedyny. Oprócz niego mamy do czynienia z przydźwiękiem (wyraźne bzyczenie, którego częstotliwość podstawowa to na ogół 50 Hz, choć najlepiej słyszalna jest jej druga harmoniczna, czyli 100 Hz), a także zakłóceniami natury radiowej i cyfrowej. Każde z tych zakłóceń powstaje w inny sposób, inne jest jego źródło i inny sposób redukcji. Szum najczęściej pochodzi z układów elektronicznych o dużym wzmocnieniu, a w domenie cyfrowej jest częstym objawem braku synchronizacji. Przydźwięk sieciowy to pochodna złego ekranowania kabli sygnałowych, problemów z masą lub braku odpowiedniego połączenia. Niekiedy, zwłaszcza gdy słychać go w niskich rejestrach, jego obecność wynika z niewłaściwego odfiltrowania napięcia zasilającego, zwykle na skutek uszkodzenia elektrolitycznych kondensatorów wygładzających napięcie po wyprostowaniu.
Przydźwięk potrafi być słyszalny w całym spektrum audio, aż do częstotliwości rzędu kiloherców. Jest to jednak na ogół fala periodyczna, co oznacza, że ma stałe i zwykle niezmienne częstotliwości, zazwyczaj harmoniczne. Można sobie z nimi poradzić za pośrednictwem banku wąsko strojonych filtrów, choć należy się liczyć także ze stratami w samym sygnale użytecznym. Zakłócenia radiowe i szum to sygnały nieperiodyczne, o niejednoznacznych częstotliwościach, a tym samym bardzo trudne do usunięcia z sygnału użytecznego. Dostępne są już jednak narzędzia, które radzą sobie z tym problemem bardzo skutecznie. Zwykle ich działanie opiera się na analizie fragmentu dźwięku, w którym pojawia się sam szum. Po jej dokonaniu, procesor aplikuje do sygnału użytecznego sygnał szumowy o takim samym charakterze pasmowym, ale z odwrotną biegunowością względem aktualnego sygnału użytecznego. Do nas należy jedynie dobór „okienka” czasowego, w którym taka obróbka będzie dokonywana, a także ustalenie jej głębokości.
W rzeczywistości jednak producenci różnie podchodzą do tego tematu, np. stosując odniesienie do poziomu maksymalnego (a nie nominalnego), zaś do pomiarów szumu i zniekształceń aplikując różnego typu tzw. krzywe ważenia czy zawężając pasmo pomiarów. Nie ma problemu, jeśli w danych technicznych pojawiają się informacje o warunkach dokonanych pomiarów, ale zwykle, zwłaszcza w sprzęcie najtańszym, nikt nie zawraca sobie tym głowy. W efekcie, poprzez nieujawnienie warunków pomiarowych, można zwiększyć poziom sygnału nawet o 12 dB, zaniżając też poziom szumów o 6 lub 9 dB (np. poprzez zastosowanie krzywej ważenia A lub C). W skrajnych przypadkach uzyska się w ten sposób wyniki „lepsze” nawet o 21 dB w porównaniu do innych urządzeń, przy mierzeniu których zachowano pełną jawność warunków pomiarowych. Przy dużej konkurencji rynkowej owa przewaga może sprawić, że nabywca zdecyduje się na zakup sprzętu, którego producent w nie do końca uczciwy, ale wciąż dozwolony prawnie sposób, uzyska na papierze większy zakres dynamiki i mniejszy poziom szumów. Na szczęście my jako konsumenci nie jesteśmy wobec tego stanu rzeczy całkowicie bezradni. Uzbrojeni w odpowiednią wiedzę możemy bez żadnych problemów samodzielnie zweryfikować najbardziej istotne dane techniczne, często będące podstawą do porównań między urządzeniami. W opisanej niżej sytuacji w sposób miarodajny dokonamy porównania zakresu dynamiki torów mikrofonowych dwóch różnych interfejsów audio. Co ciekawe, nie potrzeba do tego żadnych specjalistycznych narzędzi – wystarczy podłączyć interfejs do komputera, wskazać jego tor mikrofonowy jako wejście dla programu audio (w naszym przypadku jest to Adobe Audition), wyłączyć wszelkie dodatki w przedwzmacniaczu (fantom, tłumik, odwracanie biegunowości, filtr górnoprzepustowy, zmiana impedancji, wejście instrumentalne) i ustawić na minimum regulator czułości Gain. Do wejścia nie powinien być podłączony żaden kabel.
Krok po kroku
3. Określenie zakresu dynamiki interfejsu audio
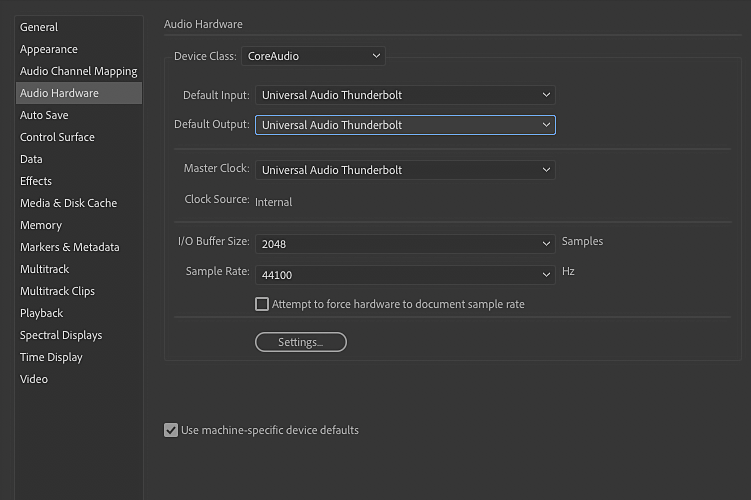
1.
Z technicznego punktu widzenia opisanej procedury nie można nazwać pomiarem, ponieważ wykonuje się ją bez odpowiednio skalibrowanych narzędzi pomiarowych. W praktyce jednak, uzyskane tą metodą wyniki będą niemal identyczne z wynikami specjalistycznych pomiarów, a poza tym lepiej oddadzą stan faktyczny w przypadku konkretnego interfejsu.

2.
W programie Adobe Audition wejdź do ustawień i w zakładce Audio Hardware wybierz wejście i wyjście interfejsu podłączonego do komputera. W zakładce Audio Channel Mapping jako domyślne wejście stereo wskaż te porty, na których znajduje się przedwzmacniacz mikrofonowy. Jeśli jest tylko jeden, wybierz go dla kanału L (Mono).

3.
Wyłącz wszystkie funkcje w przedwzmacniaczu interfejsu i ustaw Gain na minimum. Odłącz kable od wejść. Kliknij prawym klawiszem myszy na wskaźniku poziomu w Audition i wybierz funkcję Meter Input Signal, zaznaczając jednocześnie największy zakres wskazań (120 dB). Wskaźnik pokaże poziom szczytowy szumów własnych przedwzmacniacza.

4.
Kliknij File > New > Audio File. We właściwościach nowego pliku wskaż aktualne próbkowanie interfejsu, tryb kanałów określ jako Mono, a rozdzielczość bitową ustaw na 24. Kliknij OK, a następnie czerwoną kropkę w sekcji przycisków napędu, aby rozpocząć nagrywanie sygnału z wejścia wskazanego jako L (Mono).
5.
Ponieważ na wejściach interfejsu nie ma żadnego sygnału użytecznego, program zarejestruje tylko ten sygnał, który pochodzi z toru sygnałowego interfejsu, będący jego szumem własnym, zakłóceniami oraz przydźwiękiem. Po ok. 20 sekundach wyłącz nagrywanie i przyjrzyj się plikowi, przytrzymując klawisz Alt i sukcesywnie wciskając klawisz +.

6.
Powiększony sygnał to wszystko to, czego w nagrywanym materiale nie chcemy. W świecie realnym jednak nie da się tego uniknąć. Poprzez odpowiednią konstrukcję i wysoką jakość zastosowanych elementów można jedynie sprawić, by poziom tego niechcianego sygnału był jak najmniejszy. W praktyce określa on zakres dynamiki interfejsu (w odniesieniu do 0 dBfs).
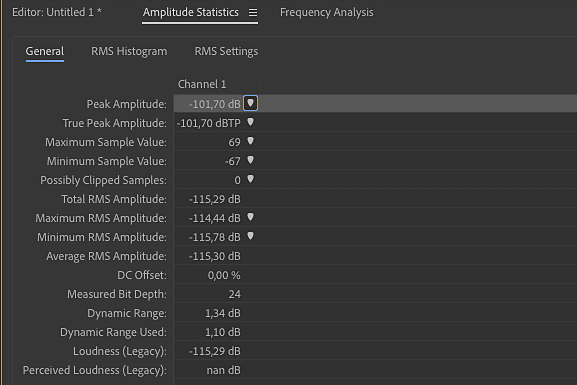
7.
Kliknij Window > Amplitude Statistics, a następnie przycisk Scan. Audition automatycznie przeskanuje zapisany plik i w tabelce zaprezentuje wszystkie jego parametry. Wartości, które najbardziej nas interesują, to Total RMS Amplitude (w praktyce to zakres dynamiki) oraz DC Offset (poziom ewentualnej składowej stałej). Tutaj wyniki są perfekcyjne: 115,29 dB i 0%.
8.
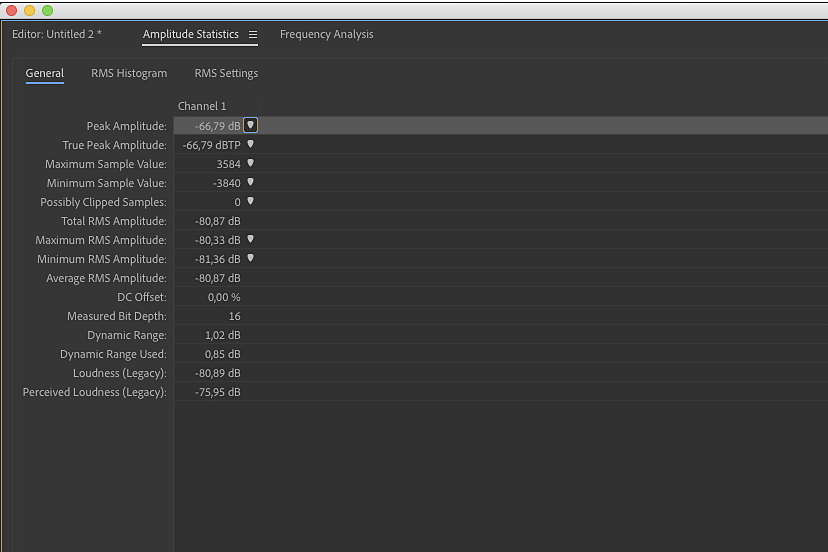
Zapisz plik jako 24-bitowy WAV mono, nadając mu nazwę interfejsu. Zamknij Audition, odłącz interfejs od komputera, podłącz drugi, który chcesz z nim porównać, i upewnij się, że jest widziany przez system. Ponownie dokonaj wszystkich opisanych wyżej czynności. Na pierwszy rzut oka widać, że uzyskane wyniki są znacząco słabsze niż poprzednio.
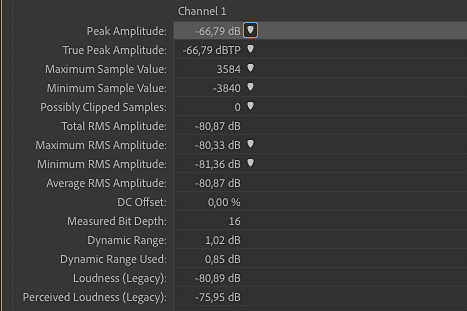
9.
Total RMS Amplitude wynosi -80,78 dB względem 0 dBfs, zatem zakres dynamiki tego wejścia to 80,78 dB. Ponadto okazało się, że plik jest 16-bitowy (Measured Bit Depth), więc konwerter tego interfejsu ma rozdzielczość 16 bitów. Jego maksymalny teoretyczny zakres dynamiki to 96 dB (16 x 6 bitów), zatem jak na tego typu urządzenie ten wynik to norma.
Krok po kroku
4. Analiza szumów własnych interfejsu audio
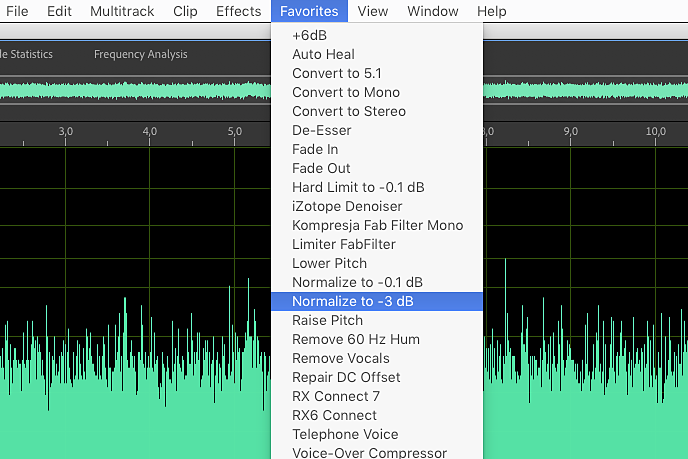
1.
Pliki, które uzyskałeś nagrywając „pusty” sygnał z interfejsów, warto poddać analizie, która może nam więcej powiedzieć o jakości torów audio. W programie Audition poddaj je obróbce z wykorzystaniem normalizacji (Favorites > Normalize to -3 dB). Wartość każdej próbki zostanie proporcjonalnie zwiększona, przy czym najgłośniejsza będzie mieć poziom -3 dBfs.
2.
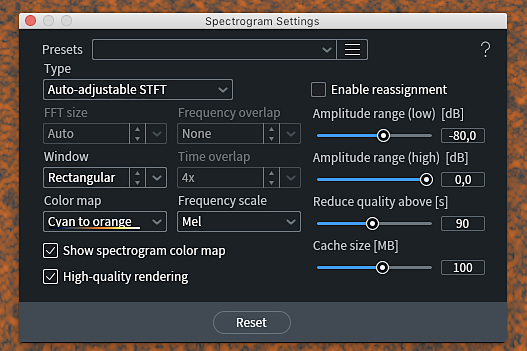
Otwórz pliki w oddzielnych zakładkach programu iZotope RX7 z widokiem spektrum. Kliknij prawym klawiszem myszy na spektrogramie i wybierz View Spectrogram Settings. Ustaw wartości pokazane na powyższej ilustracji i zamknij okno ustawień spektrogramu. Przełączając zakładki, przyjrzyj się uważnie grafikom, próbując określić różnice.
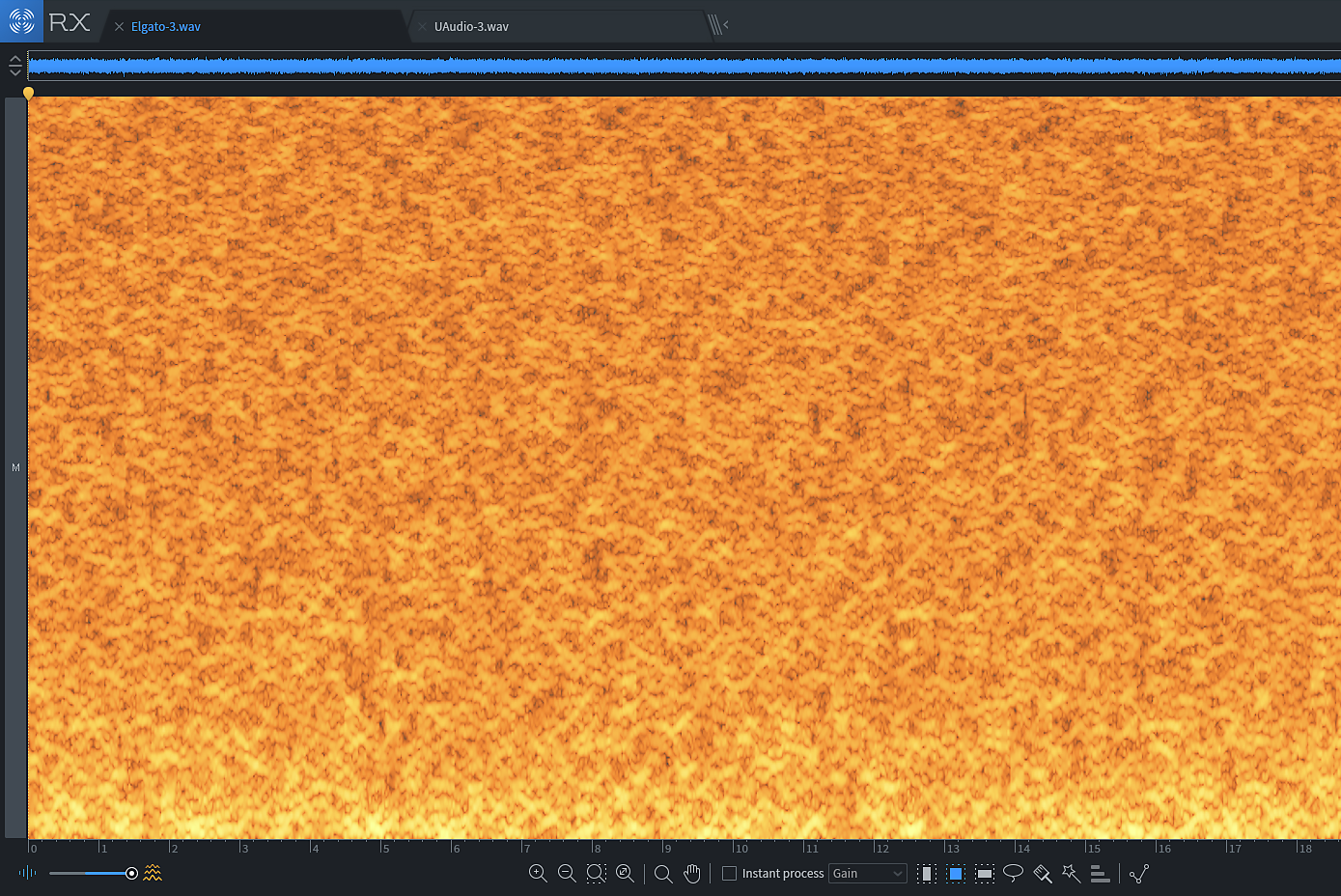
3.
Nasycenie kolorów spektrogramu pokazuje rozkład energii poszczególnych pasm szumu – czym bardziej jednolite, tym szum bardziej wyrównany energetycznie i mniej „szkodliwy”. W przypadku drugiego interfejsu mamy więcej energii w dolnym paśmie. Oznacza to zwykle nie do końca idealne odfiltrowanie zasilania – typowy kłopot tanich produktów.
Generatory szumu w DAW
W środowisku DAW i w zakresie dostępnych wtyczek znajdziemy mnóstwo narzędzi pozwalających uzyskać szum o dowolnym charakterze. Niemal każdy program wielośladowy audio oferuje własny generator szumu – czy to pod postacią wtyczek, czy też jako samodzielne narzędzie.

1.
W edytorze Adobe Audition dostępna jest funkcja Effects > Generator > Noise, pozwalająca wygenerować dowolny szum o wskazanym czasie trwania i poziomie.
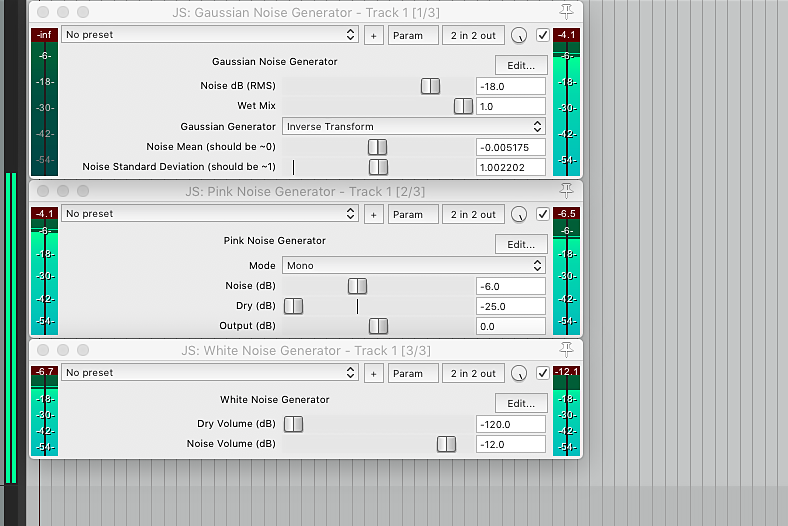
2.
W Reaperze znajdziemy trzy wtyczki generatora szumu – wszystkie w formacie JS: szum biały, szum różowy oraz generator szumu bazujący na rozkładzie Gaussa.

3.
Apple Logic X udostępnia wszechstronny generator sygnału testowego, który znajdziemy wśród wtyczek Logic > Utility. Mamy możliwość uzyskania szumów różowego i białego.
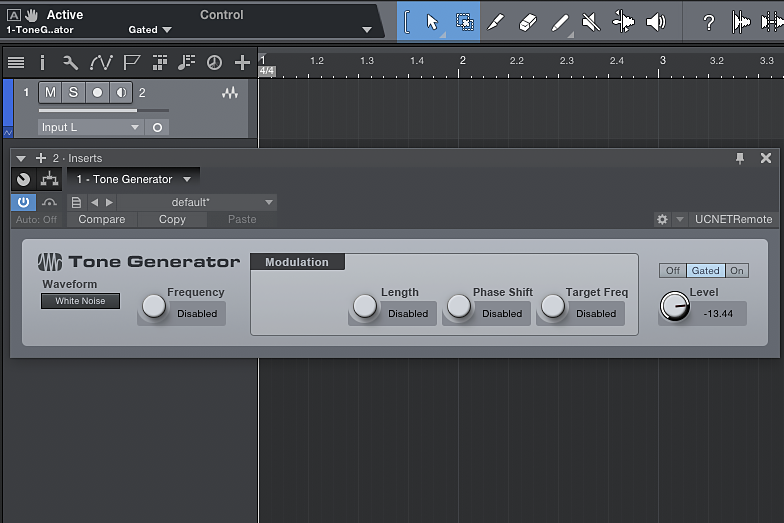
4.
Podobne narzędzie znajduje się też na pokładzie PreSonus Studio One. Wtyczki Tone Generator szukaj wśród efektów w katalogu pluginów PreSonus.
5.
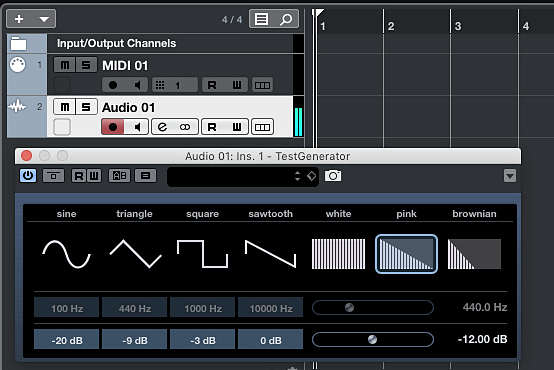
Steinberg Cubase ma własny generator szumu białego, różowego i szumu Browna, który jest częścią wtyczki Test Generator, dostępnej wśród efektów Steinberg.
6.
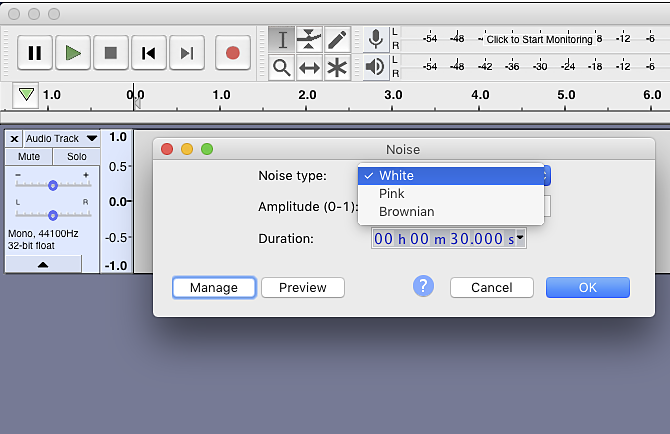
Bezpłatny wielośladowy edytor Audacity pozwala wygenerować szum na zasadzie podobnej jak Audition. Odpowiednie narzędzie znajduje się w menu Generator > Noise.
7.
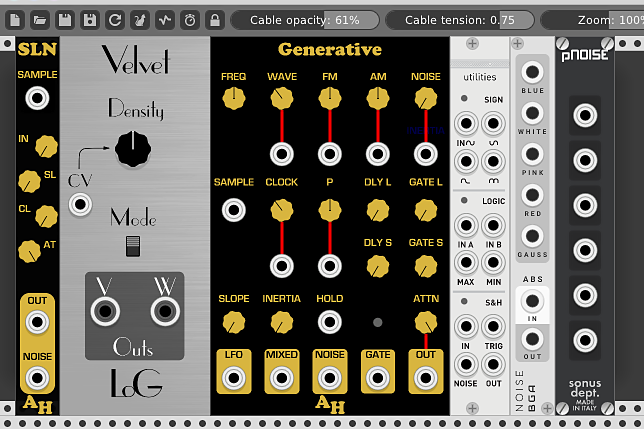
Całą gamę modułów generujących różnego typu szum można znaleźć w syntezatorach modularnych Voltage Modular, FB ModulAir czy VCV Rack.
8.
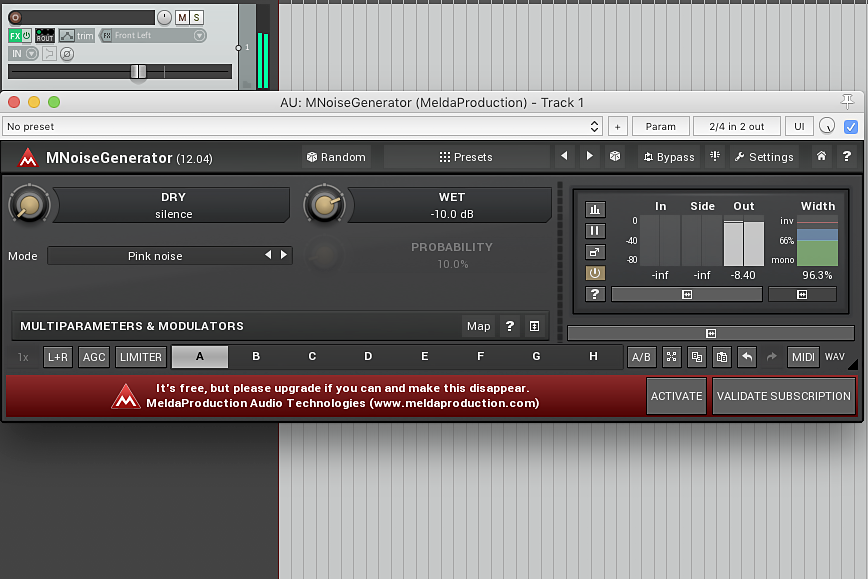
Bez wątpienia najlepszym dostępnym za darmo narzędziem do wytwarzania szumu pozostaje jednak wtyczka MNoiseGenerator, dostępna w pakiecie Melda Production Free.